What is Training Data in AI: How it Works & Explained
Published: 2 Apr 2026
You may have heard the term “Training Data” in AI and wondered how AI models learn from data.
In this guide, we will explain what training data is, why it is important, its types, how it is prepared, and its applications. By the end, you will clearly understand why training data is the foundation of any AI system.
What is Training Data in AI?
This section explains the basic meaning of training data.
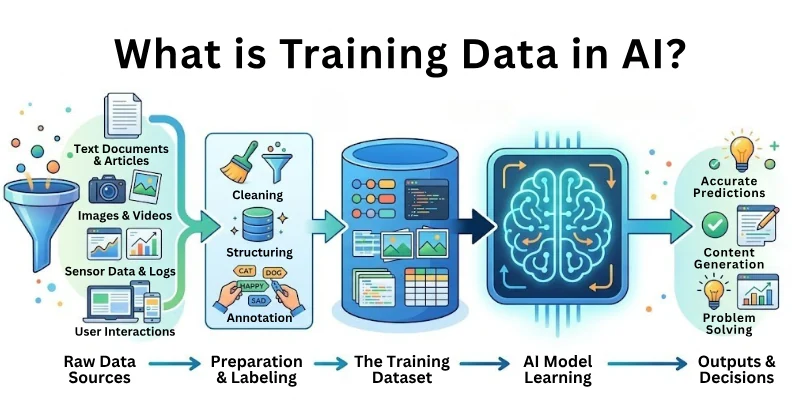
Training Data in AI refers to the dataset used to teach AI models how to make decisions or predictions. The AI learns patterns, relationships, and rules from this data to perform tasks like classification, prediction, or recognition.
Key Points
- Training data is the foundation of any AI model.
- Helps models learn patterns and make predictions.
- Must be high-quality, accurate, and relevant.
- Can be structured (tables, spreadsheets) or unstructured (images, text, audio).
- The better the training data, the better the AI performance.
Why Training Data is Important
This section explains why training data matters so much.
AI models rely entirely on the data they are trained with. Poor data leads to inaccurate predictions or biased decisions, while good data ensures the AI performs well.
Importance
- Determines the accuracy and reliability of AI models.
- Reduces errors by providing diverse and representative examples.
- Prevents bias by including fair and balanced data.
- Enables models to generalize to new, unseen data.
- Supports better decision-making and automation in real-life applications.
Types of Training Data
This section explains the different kinds of training data used in AI.
- Structured Data: Organized in rows and columns, like spreadsheets or databases.
- Unstructured Data: Includes images, videos, audio, text, and social media content.
- Labeled Data: Data with correct answers or tags used for supervised learning.
- Unlabeled Data: Data without labels, used for unsupervised learning.
- Synthetic Data: Artificially generated data used when real data is insufficient or sensitive.
- Time-Series Data: Data collected over time, used for predictions and trend analysis.
How Training Data is Prepared
This section explains the steps to prepare high-quality training data.
Preparation Steps
- Data Collection: Gather data from relevant sources.
- Data Cleaning: Remove errors, duplicates, and irrelevant data.
- Data Labeling: Assign correct labels or categories if needed.
- Data Transformation: Convert data into a format suitable for AI models.
- Data Augmentation: Create variations to increase data size (especially for images or audio).
- Data Splitting: Divide data into training, validation, and test sets for proper evaluation.
Example: For a self-driving car AI, training data includes images of roads, signs, pedestrians, and vehicles. Labeled images help the AI recognize objects accurately.
Applications of Training Data in AI
This section explains where training data is used in real-life AI systems.
Key Applications
- Image Recognition: Training AI to identify objects or faces.
- Speech Recognition: Teaching AI to understand spoken language.
- Predictive Analytics: Forecasting trends in business or finance.
- Recommendation Systems: Suggesting products or content based on user behavior.
- Healthcare Diagnostics: AI learns from patient data to detect diseases.
- Autonomous Vehicles: AI learns to detect lanes, obstacles, and traffic signs.
Advantages of Good Training Data
This section explains why having good training data is valuable.
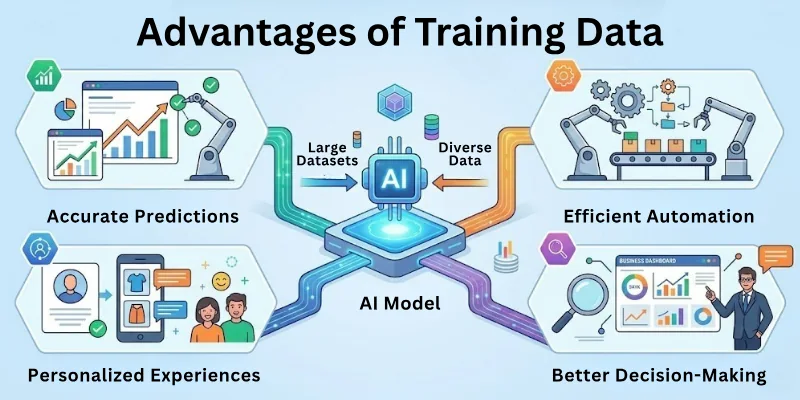
Key Advantages
- Improves AI accuracy and reliability.
- Reduces errors and mispredictions.
- Helps models generalize better to new data.
- Prevents biased decisions by including diverse examples.
- Supports faster and more effective model training.
Limitations of Training Data
This section explains the challenges and drawbacks of training data.
Main Limitations
- Collecting high-quality data can be time-consuming and costly.
- Poor data leads to biased or inaccurate models.
- Large datasets require significant storage and processing power.
- Labeling data manually is labor-intensive.
- Sensitive data may create privacy and ethical issues.
Future of Training Data
This section explains how training data is evolving in AI.
Future Trends
- Increased use of synthetic data to reduce cost and improve diversity.
- Automated data labeling using advanced tools and AI itself.
- Better handling of unstructured and streaming data.
- Focus on privacy-preserving data methods.
- Continuous improvement to ensure fair and unbiased training data.
Final Note
In this guide, we have covered what training data in AI is in great detail. You now understand its meaning, importance, types, preparation, applications, advantages, limitations, and future trends. Training data is the backbone of every AI model, and high-quality data ensures that AI works accurately and fairly.
Step by step, even beginners can understand why training data matters. Stay curious, explore more, and see how proper data is shaping AI systems around us.
Goodbye and keep learning the exciting world of AI training!
FAQs: Training Data in AI
Here are some of the most commonly asked questions related to the training data in AI:
Training data in AI is the dataset used to teach AI models how to make predictions or decisions. It contains examples that help the AI learn patterns and understand relationships in the data.
Good training data is essential because it directly affects the accuracy and reliability of AI models. Poor or biased data can lead to wrong predictions and unreliable outcomes.
The main types include structured, unstructured, labeled, unlabeled, synthetic, and time-series data. Each type serves different AI tasks and learning methods.
Preparation involves collecting, cleaning, labeling, transforming, augmenting, and splitting data into training, validation, and test sets. Proper preparation ensures the AI learns effectively.
In image recognition, training data consists of labeled images showing objects, faces, or scenes. The AI learns to identify patterns so it can recognize new images accurately.
High-quality training data improves accuracy, reduces errors, helps models generalize, prevents bias, and speeds up training. It is critical for reliable AI performance.
Challenges include high cost, time-consuming collection, labeling effort, large storage needs, and privacy concerns. Poor data quality can lead to inaccurate AI models.
No, most AI models cannot learn or make predictions without training data. The data provides examples and patterns that the AI uses to understand tasks.
Synthetic training data is artificially generated data used when real data is limited or sensitive. It helps expand datasets and improve AI performance without privacy risks.
The future includes automated labeling, synthetic data generation, privacy-preserving data methods, and handling of streaming or unstructured data. Better training data will continue to improve AI accuracy and fairness.






- Be Respectful
- Stay Relevant
- Stay Positive
- True Feedback
- Encourage Discussion
- Avoid Spamming
- No Fake News
- Don't Copy-Paste
- No Personal Attacks
- Be Respectful
- Stay Relevant
- Stay Positive
- True Feedback
- Encourage Discussion
- Avoid Spamming
- No Fake News
- Don't Copy-Paste
- No Personal Attacks
