What is Dataset Bias in AI: How it Works & Explained
Published: 3 Apr 2026
You may have heard about AI making unfair or inaccurate decisions and wondered why it happens. In this guide, we will explain what dataset bias is, why it occurs, its types, causes, effects, real-world examples, how to detect it, and ways to mitigate it.
By the end, even beginners will understand why dataset bias is a critical challenge in AI.
What is Dataset Bias in AI?
This section explains the basic meaning of dataset bias.
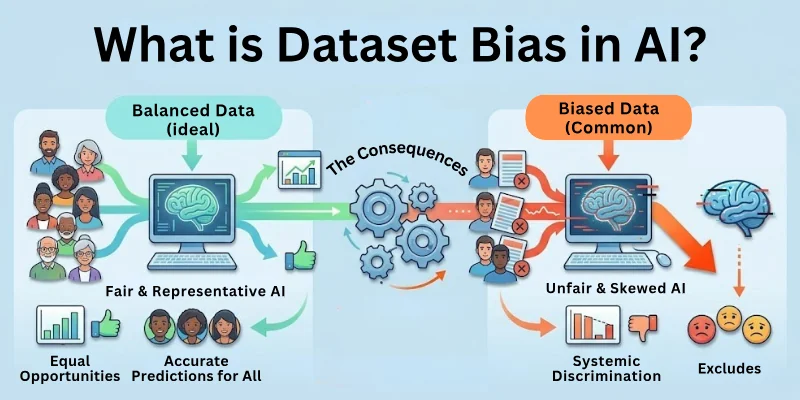
Dataset bias in AI occurs when the training data used to teach a model is not representative of the real world. As a result, AI systems may make inaccurate predictions, favor certain groups, or fail to generalize properly.
Key Points
- Bias arises from imbalanced, incomplete, or unfair data.
- Leads to skewed or unreliable AI decisions.
- Can affect predictions, classifications, or recommendations.
- Common in datasets involving humans, images, language, or finance.
- Preventing bias ensures AI is fair and accurate.
Why Dataset Bias Matters
This section explains why dataset bias is important to understand.
AI systems are only as good as the data they learn from. Biased data can amplify social inequalities, reduce reliability, and damage trust in AI systems.
Importance
- Ensures AI makes fair and accurate decisions.
- Prevents discrimination or unfair treatment.
- Improves generalization to new, real-world scenarios.
- Maintains trust in AI applications.
- Helps comply with legal and ethical standards.
Types of Dataset Bias
This section explains the main types of dataset bias.
- Selection Bias: Occurs when the data collected does not represent the entire population.
- Measurement Bias: Happens when data is measured or recorded inaccurately.
- Sampling Bias: Arises when some groups are overrepresented or underrepresented in the dataset.
- Label Bias: Happens when incorrect or inconsistent labels are used in supervised learning.
- Exclusion Bias: Occurs when important data features or groups are missing.
- Historical Bias: Arises when past data reflects existing prejudices or inequalities.
Causes of Dataset Bias
This section explains common causes that create dataset bias.
Main Causes
- Poor data collection methods that miss certain groups.
- Human errors in labeling or recording data.
- Limited or unrepresentative sample sizes.
- Societal or historical prejudices reflected in data.
- Over-reliance on specific sources rather than diverse datasets.
Effects of Dataset Bias
This section explains how bias impacts AI systems.
Main Effects
- AI may make unfair decisions in hiring, lending, or healthcare.
- Reduces accuracy and reliability of predictions.
- Leads to loss of trust from users and stakeholders.
- Can cause legal and ethical issues.
- Limits the ability of AI to generalize to new scenarios.
Example: A facial recognition AI trained mostly on light-skinned faces may fail to recognize dark-skinned faces accurately, leading to errors or unfair outcomes.
How to Detect Dataset Bias
This section explains how to identify bias in datasets.
Detection Methods
- Data auditing: Check if all groups are represented fairly.
- Statistical analysis: Measure distribution of classes and features.
- Model performance testing: Evaluate accuracy across different groups.
- Cross-validation: Test models on diverse and independent datasets.
- Bias metrics: Use fairness metrics like demographic parity or equalized odds.
How to Mitigate Dataset Bias
This section explains practical steps to reduce bias in AI systems.
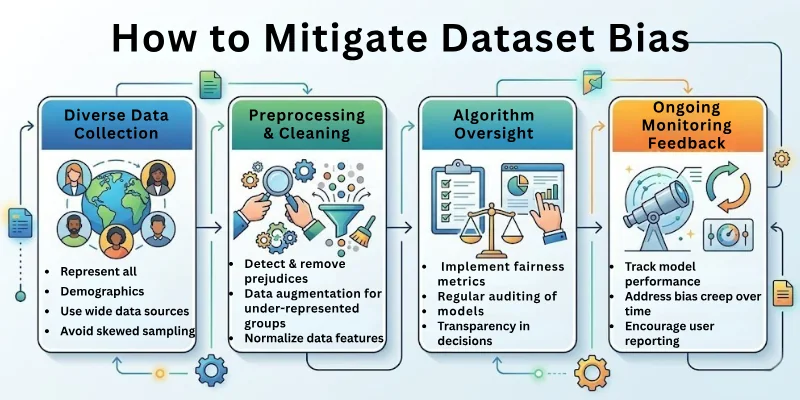
Mitigation Techniques
- Collect diverse and representative data covering all groups.
- Clean and preprocess data to remove errors and inconsistencies.
- Use data augmentation to balance underrepresented classes.
- Apply fairness-aware algorithms during model training.
- Regularly monitor and update models to handle changing data.
- Include human oversight to review decisions and outputs.
Applications and Real-World Examples
This section explains where dataset bias is a problem and how it affects AI applications.
Examples
- Healthcare: Biased patient data can lead to wrong diagnoses or treatment recommendations.
- Hiring Tools: AI trained on historical resumes may favor certain genders or ethnicities.
- Finance: Loan approval systems may unfairly reject minority applicants.
- Facial Recognition: Performance differs across skin tones due to unbalanced datasets.
- Marketing: Recommendations may exclude certain groups due to biased data.
Future of Dataset Bias in AI
This section explains how bias in datasets is being addressed and what to expect.
Future Trends
- Increased focus on fairness, ethics, and accountability in AI.
- Use of synthetic and augmented data to reduce underrepresentation.
- Automated bias detection and mitigation tools.
- Stricter regulations and guidelines for AI dataset creation.
- Continuous improvement of inclusive and representative datasets.
Final Note
In this guide, we have covered what dataset bias in AI is in very great detail. You now understand its meaning, types, causes, effects, detection methods, mitigation techniques, real-world examples, and future trends. Dataset bias is one of the biggest challenges in building fair and accurate AI systems, and handling it properly ensures that AI works responsibly and reliably.
Even beginners can now see why high-quality, diverse, and balanced data is essential. Stay aware, explore more, and remember that fairness starts with the data we feed into AI.
Goodbye and keep learning responsibly about AI!
FAQs: Dataset Bias in Artificial Intelligence
Here are some of the most commonly asked questions related to the dataset bias in AI:
Dataset bias in AI happens when the training data is not representative of the real world, causing AI to make inaccurate or unfair predictions. It affects reliability and fairness in decision-making.
It is important because biased datasets can lead to discrimination or errors in AI applications. Addressing bias ensures models are fair, accurate, and trustworthy.
Common types include selection bias, measurement bias, sampling bias, label bias, exclusion bias, and historical bias. Each type affects AI performance differently.
Bias can cause AI to misclassify, favor certain groups, or produce unfair outcomes. It reduces accuracy and trust in AI models across applications.
Causes include limited or unrepresentative data, human labeling errors, historical prejudices, and poor data collection methods. These factors create skewed learning for AI models.
Yes, by auditing the dataset, analyzing class distributions, checking for missing groups, and evaluating sample representation, bias can be detected before training.
Bias can be reduced by collecting diverse data, preprocessing and cleaning datasets, augmenting underrepresented groups, and using fairness-aware algorithms. Continuous monitoring also helps.
Examples include facial recognition misidentifying people of certain skin tones, hiring AI favoring one gender, or loan approval AI rejecting minority applicants. These biases stem from unbalanced datasets.
Biased datasets in healthcare can lead to wrong diagnoses or unequal treatment. Ensuring diverse and representative patient data is critical for fair outcomes.
The future involves automated bias detection, synthetic data generation, better regulations, inclusive datasets, and fairness-focused AI tools. These improvements aim to make AI more accurate and ethical.






- Be Respectful
- Stay Relevant
- Stay Positive
- True Feedback
- Encourage Discussion
- Avoid Spamming
- No Fake News
- Don't Copy-Paste
- No Personal Attacks
- Be Respectful
- Stay Relevant
- Stay Positive
- True Feedback
- Encourage Discussion
- Avoid Spamming
- No Fake News
- Don't Copy-Paste
- No Personal Attacks
